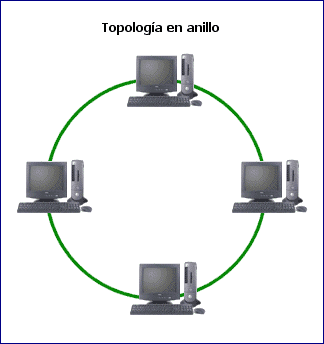
Internet grid
La computación Grid es el conjunto de recursos informáticos
de varias ubicaciones para alcanzar un objetivo común. La rejilla puede ser
pensado como un sistema distribuido con cargas de trabajo no interactivos que
involucran un gran número de archivos. La computación grid se distingue de los
sistemas de computación de alto rendimiento convencionales, tales como la
computación en clúster en que las computadoras de la red tienen cada nodo
establecido para realizar una tarea / aplicación diferente. computadoras cuadrícula también tienden a ser
más heterogéneo y disperso geográficamente (por lo tanto no acoplado
físicamente) que las computadoras de racimo. Aunque una sola rejilla puede ser
dedicado a una aplicación particular, comúnmente una rejilla se utiliza para
una variedad de propósitos. Grids menudo se construyen con bibliotecas de
software middleware rejilla de uso general.
Tamaño de la cuadrícula varía una cantidad considerable.
Grids son una forma de computación distribuida por el que un "super
computadora virtual" se compone de muchos ordenadores débilmente acoplados
en red que actúan en conjunto para realizar tareas grandes. Para ciertas
aplicaciones, "distribuido" o "grid" computación, puede ser
visto como un tipo especial de computación paralela que se basa en equipos
completos (con CPUs a bordo, almacenamiento, fuentes de alimentación,
interfaces de red, etc.) conectados a una red (privada o público) por una
interfaz de red convencional, tal como Ethernet. Esto está en contraste con la
noción tradicional de una supercomputadora, que tiene muchos procesadores
conectados por un bus local de computación de alta velocidad.
Descripción
Grid computing combina computadoras de múltiples dominios
administrativos para alcanzar un objetivo común, [3] para resolver una sola
tarea, y pueden luego desaparecen con la misma rapidez.
Una de las principales estrategias de la computación grid es
el uso de middleware para dividir y repartir piezas de un programa entre varios
ordenadores, a veces hasta varios miles. La computación grid implica la
computación de una manera distribuida, que también puede implicar la agregación
de grupos a gran escala.
El tamaño de una cuadrícula puede variar desde pequeños
confinados a una red de estaciones de trabajo dentro de una empresa, por
ejemplo, a las grandes colaboraciones públicas, a través de muchas empresas y
redes. "La noción de una rejilla confinada también se conoce como la
cooperación intra-nodos, mientras que la noción de una red más grande, más
amplio por lo tanto puede referirse a una inter-nodos cooperación".
Grids son una forma de computación distribuida por el que un
"super computadora virtual" se compone de muchos ordenadores
débilmente acoplados en red que actúan en conjunto para realizar tareas muy
grandes. Esta tecnología se ha aplicado a computacionalmente problemas
científicos, matemáticos y académicos intensivos a través de la computación
voluntaria, y se utiliza en las empresas comerciales para aplicaciones tan
diversas como el descubrimiento de fármacos, la previsión económica, análisis
sísmico y la espalda de procesamiento de datos de oficinas en apoyo a e-
comercio y los servicios web.
La coordinación de las aplicaciones en Grids puede ser una
tarea compleja, especialmente cuando coordinar el flujo de información a través
de los recursos de computación distribuida. Sistemas de flujo de trabajo de
cuadrícula se han desarrollado como una forma especializada de un sistema de
gestión de flujo de trabajo diseñado específicamente para componer y ejecutar
una serie de etapas de manipulación computacional o datos, o un flujo de
trabajo, en el contexto de cuadrícula.
Comparación de las
redes y los superordenadores convencionales
"Distribuida" o "grid" computación en
general es un tipo especial de computación paralela que se basa en equipos
completos (con CPUs a bordo, almacenamiento, fuentes de alimentación, interfaces
de red, etc.) conectados a una red (privada, pública o Internet) por un
hardware de los productos básicos de interfaz de red producción convencional,
en comparación con la menor eficiencia de diseñar y construir un pequeño número
de superordenadores personalizados. La desventaja principal es el rendimiento
que los diferentes procesadores y áreas de almacenamiento locales no cuentan
con conexiones de alta velocidad. Este arreglo es por lo tanto muy adecuado
para aplicaciones en las que múltiples cálculos paralelos pueden llevarse a
cabo de forma independiente, sin la necesidad de comunicar los resultados
intermedios entre los procesadores. [5] La escalabilidad de gama alta de las
redes geográficamente dispersa es en general favorable, debido a la baja necesidad
para la conectividad entre nodos relativos a la capacidad de la Internet
pública.
También hay algunas diferencias en la programación e
implementación. Puede ser costoso y difícil de escribir programas que se pueden
ejecutar en el entorno de una supercomputadora, que puede tener un sistema
operativo personalizado, o requerir el programa para hacer frente a problemas
de concurrencia. Si un problema puede ser paralelizado adecuadamente, una capa
"delgada" de infraestructura "red" puede permitir que los
programas convencionales, independientes, dada una parte diferente del mismo
problema, a ejecutarse en múltiples máquinas. Esto hace que sea posible
escribir y depurar en una sola máquina convencional, y elimina las
complicaciones debido a varias instancias del mismo programa que se ejecuta en
la misma memoria compartida y el espacio de almacenamiento al mismo tiempo.
Consideraciones sobre
el diseño y las variaciones
Esta sección no citar todas las referencias o fuentes. Por
favor, ayudar a mejorar esta sección añadiendo citas de fuentes confiables.
Material de referencias puede ser impugnado y eliminado. (Agosto de 2013)
Una característica de las redes distribuidas es que pueden
formarse a partir de los recursos informáticos pertenecientes a múltiples
individuos u organizaciones (conocidos como múltiples dominios
administrativos). Esto puede facilitar las transacciones comerciales, como en
utility computing, o que sea más fácil de montar redes de computación
voluntaria.
Una desventaja de esta función es que los equipos que
realicen efectivamente los cálculos pueden no ser del todo fiable. Los
diseñadores del sistema deben por tanto adoptar medidas para evitar un mal
funcionamiento o participantes maliciosos de la producción falsa, engañosa o
resultados erróneos, y de utilizar el sistema como un vector de ataque. Esto a
menudo implica la asignación de trabajo al azar a diferentes nodos
(presumiblemente con diferentes propietarios) y la comprobación de que al menos
dos nodos diferentes informan la misma respuesta para una unidad de trabajo
dado. Las discrepancias identificarían nodos defectuosos y maliciosos. Sin
embargo, debido a la falta de control central sobre el hardware, no hay ninguna
manera de garantizar que los nodos no se caiga fuera de la red en momentos
aleatorios. Algunos nodos (como ordenadores portátiles o los clientes de acceso
telefónico a Internet) también pueden estar disponibles para el cálculo, pero
no la red de comunicaciones por períodos impredecibles. Estas variaciones se
pueden acomodar mediante la asignación de unidades de trabajo grandes (lo que
reduce la necesidad de conectividad de red continua) y la reasignación de
unidades de trabajo cuando un nodo dado no informa sus resultados en el tiempo
esperado.

Los impactos de la confianza y la disponibilidad en
dificultad el rendimiento y el desarrollo pueden influir en la elección de si
se debe desplegar en un clúster dedicado, a ralentí máquinas internas a la
organización en desarrollo, o con una red externa abierta de voluntarios o
contratistas. En muchos casos, los nodos participantes deben confiar en el
sistema central no abusar del acceso que se concede, al interferir con el
funcionamiento de otros programas, destrozando la información almacenada, la
transmisión de datos privados, o la creación de nuevos agujeros de seguridad.
Otros sistemas emplean medidas para reducir la cantidad de nodos de confianza
"cliente" debe colocar en el sistema central como la colocación de
aplicaciones en máquinas virtuales.
Los sistemas públicos o aquellos dominios administrativos
que cruzan (incluyendo diferentes departamentos de la misma organización) a
menudo resultan en la necesidad de ejecutar en sistemas heterogéneos, con
diferentes sistemas operativos y arquitecturas de hardware. Con muchos idiomas,
existe un compromiso entre la inversión en desarrollo de software y el número
de plataformas que puede ser soportada (y por lo tanto el tamaño de la red
resultante). Idiomas entre plataformas pueden reducir la necesidad de hacer
esta compensación, aunque potencialmente a expensas de alto rendimiento en
cualquier nodo dado (interpretación para funcionar en tiempo debido o la falta
de optimización de la plataforma en particular). Existen diversos proyectos científicos
y comerciales para aprovechar una red asociada en particular o con el propósito
de la creación de nuevas redes. BOINC es una común para varios proyectos
académicos que buscan voluntarios públicos; más se enumeran al final del
artículo.
De hecho, el middleware se puede ver como una capa entre el
hardware y el software. En la parte superior del middleware, una serie de áreas
técnicas tienen que ser considerados, y estos pueden o no ser middleware
independiente. Áreas ejemplo incluyen gestión de SLA, Confianza y Seguridad,
gestión de la organización virtual, gestión de licencias, Portales y gestión de
datos. Estas áreas técnicas pueden ser atendidos en una solución comercial,
aunque la vanguardia de cada área se encuentra a menudo en los proyectos específicos
de investigación que examinan el campo.
El lado del proveedor
El mercado global de rejilla comprende varios mercados
específicos. Estos son el mercado de middleware grid, el mercado de
aplicaciones de red habilitada, el mercado de la informática de servicios
públicos, y el-as-a-service software (SaaS) de mercado.
Middleware Grid es un producto de software específico, que
permite el intercambio de recursos heterogéneos, y organizaciones virtuales.
Está instalado e integrado en la infraestructura existente de la empresa
involucrados o empresas, y proporciona una capa especial colocado entre la
infraestructura heterogénea y las aplicaciones de usuario específicas.
Principales middleware grid Globus Toolkit son, gLite y UNICORE.
Utility computing se refiere como la prestación de grid
computing y aplicaciones como el servicio, ya sea como una utilidad de rejilla
abierta o como una solución de hosting para una organización o un VO. Los
principales actores en el mercado de la informática de utilidad son Sun
Microsystems, IBM y HP.
Aplicaciones de redes habilitadas son aplicaciones de
software específicas que pueden utilizar la infraestructura de red. Esto se
hace posible por el uso de middleware rejilla, como se ha señalado
anteriormente.
Software como servicio (SaaS) es "software que es
propiedad, entregado y gestionar de forma remota por uno o más
proveedores." (Gartner 2007) Además, las aplicaciones SaaS se basan en un
único conjunto de definiciones de códigos y de datos comunes. Se consumen en un
modelo de uno-a-muchos, y SaaS utiliza un As You Go modelo (de reparto) o un
modelo de suscripción que se basa en el uso de pago. Los proveedores de SaaS no
poseen necesariamente los propios recursos informáticos, que son necesarios
para ejecutar sus SaaS. Por lo tanto, los proveedores de SaaS pueden aprovechar
el mercado de utility computing. El mercado de la informática de utilidades
proporciona recursos de computación para los proveedores de SaaS.
El lado del usuario
Para las empresas que en el lado de la demanda o usuario del
mercado de la computación grid, los diferentes segmentos tienen implicaciones
significativas para su estrategia de implementación de TI. La estrategia de
implementación de TI, así como el tipo de inversiones en TI hecho son aspectos
relevantes para los usuarios potenciales de la cuadrícula y desempeñan un papel
importante para la adopción de cuadrícula.
CPU de barrido
CPU-barrido, ciclo de recolección de residuos, o la
computación compartida crea una "red" de los recursos no utilizados
en una red de participantes (ya sea a nivel mundial o internas en una
organización). Normalmente esta técnica utiliza escritorio ciclos de
instrucción de computadoras que otro modo se perdería en la noche, durante el
almuerzo, o incluso en los segundos dispersos a lo largo del día en que el
equipo está a la espera de la entrada del usuario o dispositivos lentos. En la
práctica, los sistemas participantes también donar cierta cantidad de soporte
de espacio de almacenamiento en disco, memoria RAM, y ancho de banda, además de
energía de la CPU en bruto.
Muchos proyectos de computación voluntaria, como BOINC,
utilizan el modelo de barrido de la CPU. Puesto que los nodos son propensos a
ir "fuera de línea" de vez en cuando, ya que sus propietarios
utilizan sus recursos para su objetivo principal, este modelo debe estar
diseñado para manejar este tipo de contingencias.
Historia
La computación grid término se originó en la década de 1990
como una metáfora de poder de toma de equipo como de fácil acceso como una red
de energía eléctrica. La metáfora red eléctrica para la informática accesible
rápidamente se convirtió canónica cuando Ian Foster y Carl Kesselman publicaron
su trabajo seminal, "The Grid: Modelo para una nueva infraestructura informática"
(1999).
Barrido de la CPU y la computación voluntaria se
popularizaron a partir de 1997 por distributed.net y más tarde en 1999 por SETI
@ home para aprovechar el poder de los ordenadores conectados en red a nivel
mundial, con el fin de resolver problemas de investigación intensivo de la CPU.
 Las ideas de la red (incluidos los de computación
distribuida, la programación orientada a objetos, y los servicios Web) se
reunieron por Ian Foster, Carl Kesselman, y Steve Tuecke, considerados por
muchos como los "padres de la red". liderado los esfuerzos para
crear el Globus Toolkit incorporando no sólo la gestión de la computación, sino
también la gestión del almacenamiento, aprovisionamiento de seguridad, el
movimiento de datos, monitoreo y un conjunto de herramientas para el desarrollo
de servicios adicionales sobre la base de la misma infraestructura, incluido un
acuerdo de negociación, mecanismos de notificación, los servicios de
activación, y agregación de información. Mientras que el Globus Toolkit sigue
siendo el estándar de facto para soluciones de redes edificio, una serie de
otras herramientas se han construido que responder algún subconjunto de los
servicios necesarios para crear una empresa o rejilla global.
Las ideas de la red (incluidos los de computación
distribuida, la programación orientada a objetos, y los servicios Web) se
reunieron por Ian Foster, Carl Kesselman, y Steve Tuecke, considerados por
muchos como los "padres de la red". liderado los esfuerzos para
crear el Globus Toolkit incorporando no sólo la gestión de la computación, sino
también la gestión del almacenamiento, aprovisionamiento de seguridad, el
movimiento de datos, monitoreo y un conjunto de herramientas para el desarrollo
de servicios adicionales sobre la base de la misma infraestructura, incluido un
acuerdo de negociación, mecanismos de notificación, los servicios de
activación, y agregación de información. Mientras que el Globus Toolkit sigue
siendo el estándar de facto para soluciones de redes edificio, una serie de
otras herramientas se han construido que responder algún subconjunto de los
servicios necesarios para crear una empresa o rejilla global.
En 2007 el término cloud computing entró en popularidad, que
es conceptualmente similar a la definición de Foster canónica de grid computing
(en términos de recursos informáticos que se consumen en forma de electricidad
es de la red eléctrica). De hecho, grid computing es a menudo (pero no siempre)
están asociados con la entrega de sistemas de computación en nube como lo
ejemplifica el sistema AppLogic de 3Tera.
Rápidas
supercomputadoras virtuales
A partir de 2014 junio de Bitcoin Red. - 1166652 PFLOPS
A partir de abril de 2013, Folding @ home -. 11,4 x
86-equivalente (5,8 "nativos") PFLOPS [9]
A partir de marzo de 2013, en BOINC -. Procesamiento en
promedio 9.2 PFLOPS
En abril de 2010, de MilkyWay @ Home calcula en más de
1,6 PFLOPS, con una gran cantidad de este trabajo que viene de GPUs.
En abril de 2010, SETI @ Home calcula promedios de datos
de más de 730 TFLOPS.
En abril de 2010, Einstein @ Home está crujiendo más de
210 TFLOPS.
A junio de 2011, GIMPS está sosteniendo 61 TFLOPS.
Proyectos y Aplicaciones
Lista de proyectos de
computación distribuida
Grid computing ofrece una manera de resolver los problemas
de Gran reto como el plegamiento de proteínas, modelado financiero, simulación
de terremoto, y la modelización del clima / tiempo. Rejillas ofrecen una manera
de utilizar los recursos de tecnología de la información de manera óptima
dentro de una organización. También proporcionan un medio para ofrecer
tecnología de la información como una utilidad para los clientes comerciales y
no comerciales, con los clientes pagando sólo por lo que utilizan, al igual que
con la electricidad o el agua.
La computación grid está siendo aplicada por Nacional de
Tecnología de la rejilla de la Fundación Nacional de la Ciencia, de la NASA
Información Power Grid, Pratt & Whitney, Bristol-Myers Squibb Co. y American
Express.
Definiciones
Hoy en día hay muchas definiciones de la computación grid:
 En su artículo "¿Qué es la Red? Una lista de control
de tres puntos ", Ian Foster, enumera estos atributos principales:
En su artículo "¿Qué es la Red? Una lista de control
de tres puntos ", Ian Foster, enumera estos atributos principales:
Los recursos informáticos no se administran de forma
centralizada.
Se utilizan estándares abiertos.
Se logra la calidad no trivial de servicio.
Plaszczak / Wellner: definen la tecnología de redes como
"la tecnología que permite el aprovisionamiento de virtualización de
recursos, a la carta, y el servicio (de recursos) para compartir entre las
organizaciones."
IBM define grid computing como "la capacidad,
utilizando un conjunto de estándares y protocolos abiertos, para tener acceso a
aplicaciones y datos, poder de procesamiento, capacidad de almacenamiento y una
amplia gama de otros recursos informáticos a través de Internet. Una red es un
tipo de paralelo y sistema distribuido que permite compartir, seleccionar, y la
agregación de los recursos distribuidos a través de 'múltiples' dominios
administrativos basados en su (recursos) la disponibilidad, capacidad,
rendimiento, costo y requisitos de los usuarios la calidad de servicio ".
Un ejemplo anterior de la noción de la informática como la
utilidad fue en 1965 por el MIT Fernando Corbató. Corbató y los otros
diseñadores del sistema operativo Multics imaginaron una instalación informática
que opera "como una compañía de electricidad o agua empresa".
Buyya / Venugopal [28] definir cuadrícula como "un tipo
de sistema paralelo y distribuido que permite compartir, seleccionar, y la
agregación de recursos autónomos distribuidos geográficamente de forma dinámica
en tiempo de ejecución en función de su disponibilidad, capacidad, rendimiento,
coste y calidad- de los usuarios de Servicio requisitos ".
CERN, uno de los mayores usuarios de la tecnología de redes,
hablar de The Grid: ". Un servicio para compartir el poder informático y
la capacidad de almacenamiento de datos a través de Internet"
.gif)